Her research focuses on PD-L1, a protein that has gained much popularity in a field that has been under the spotlight for some time now: cancer immunotherapy. Liesbeth and her lab are specifically assessing programmed death ligand 1 (PD-L1) in non-small cell lung cancer (NSCLC).
Prescribing the correct immunotherapy
“Immunotherapy has very beneficial effects, particularly in lung cancer,” explains Liesbeth. The percentage of tumor cells positive for PD-L1 in NSCLC has significant consequences on the choice of this expensive treatment since it predicts its effectiveness. Therefore, the proportion of the protein must be calculated to aid clinicians in prescribing the correct course of treatment.
This is calculated by specialized pathologists, an arduous task prone to inter- and intra-observer variability, as Liesbeth describes: “Pulmonary pathologists are finding it difficult to score PD-L1 on lung biopsies and disagree in 15-20% of all cases. This has been extensively assessed in the literature.”
AI provides guidance
“Aiforia seemed like the most approachable, easy-to-use solution,” Liesbeth explains why she applied to aiForward. Using Aiforia® Create, Liesbeth has already trained her own deep learning AI model to calculate PD-L1 in a speedy and consistent manner. “We annotated everything, about 60 slides, in just a few weeks, and it was actually quite easy. Easier than I expected it to be, and I expected it to take much longer,” she describes the training process.
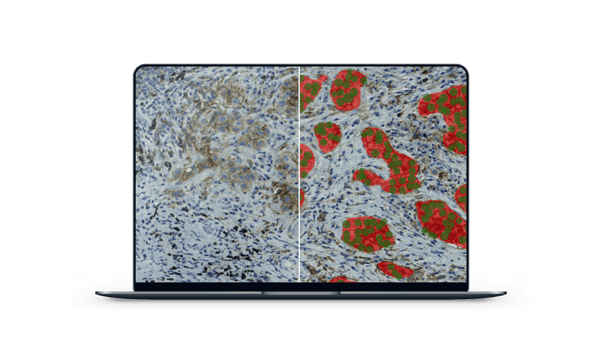
“Annotation Assistant really saves you a lot of time. It also brings up the more difficult areas that I myself would not have realized to annotate. It really made the algorithm better,” she adds, having used Aiforia’s new active learning tool to speed up her AI model creation.
What was the AI model trained to detect and analyze?
- Tissue: high-quality tissue (segmentation)
- Tumor: tumor vs other tissue (segmentation) within the high-quality tissue
- Positivity: PD-L1 positive vs negative tumor nuclei (object detection) within the tumor
- The outcome is the percentage of PD-L1 positive tumor nuclei
How did the AI model perform?
For the base AI model (not generalized to the other workups yet): Error % less than 0.5% for all semantic segmentation layers and about 9% error for object detection. On a whole slide level, the agreement to the gold standard is approximately 80%, which is equally accurate as pathologists themselves doing the task.
Analysis underway
Training is done, and now, with the PD-L1-detecting AI model in her hands, Liesbeth has already started the analysis, with the support of the pulmonary pathologists, to validate the results.
Liesbeth explains: "We are now aiming to validate this AI model in other laboratory workups as well, including different antibodies and scanners. We will describe the steps that are needed to adapt an existing AI model to a new, local laboratory workup (domain adaptation). This is a very relevant research question because many algorithms exist nowadays, but very few are reliable in new circumstances, especially in immunohistochemistry, where there is great variation between laboratories. There are no clear guidelines on how to adapt an existing pathology algorithm to a new workup yet. As far as I know, this is the first multi-center domain adaptation study for medical image analysis.
“Aiforia's AI really does something that we could not do otherwise, and the results are looking good.”
Expecting to finish her aiForward project soon, this researcher transformed from not knowing anything about AI to creating her own deep learning AI model in just a few weeks.
"The scientists and support team at Aiforia respond very quickly and have a lot of technical expertise. It has been very easy to work with Aiforia. I especially like that you don’t have to worry about AI hyper-parameters and storage issues but can focus on annotations and AI model performance," she summarized her experience working with Aiforia.
Read more case studies: